分布式Session的几种实现方式
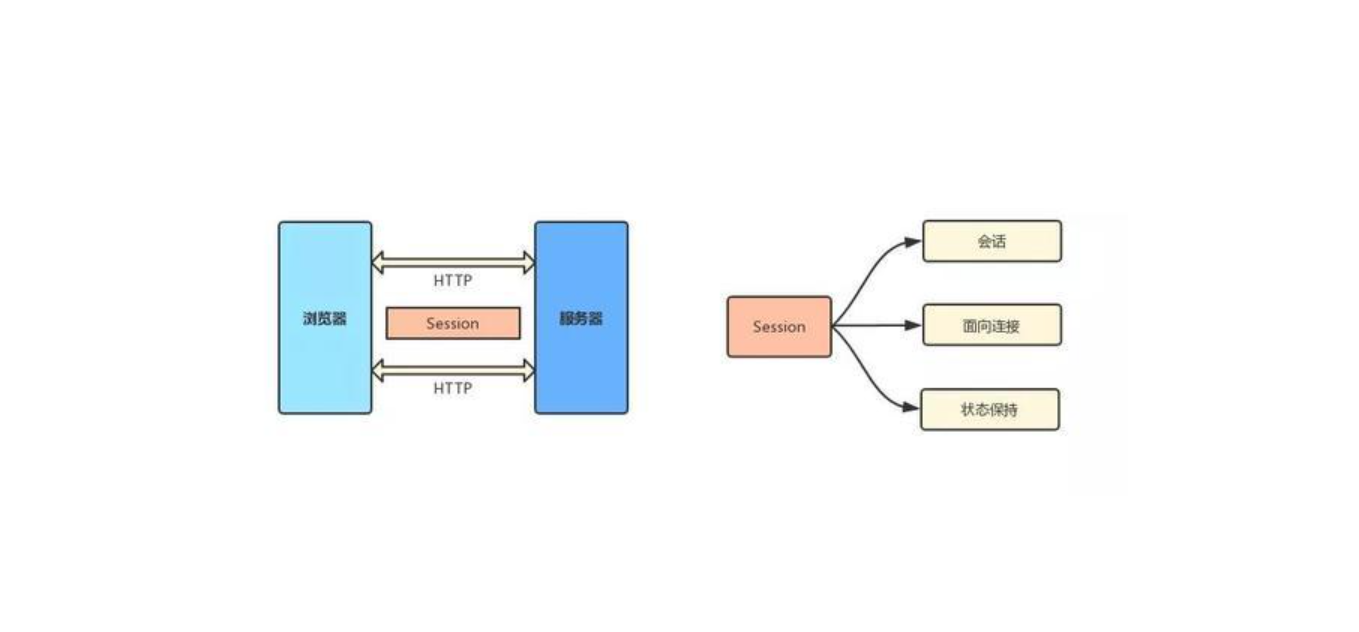
分布式Session的几种实现方式1 cookie和session的区别和联系 cookie是本地客户端用来存储少量数据信息的,保存在客户端,用户能够很容易的获取,安全性不高,存储的数据量小 session是服务器用来存储部分数据信息,保存在服务器,用户不容易获取,安全性高,储存的数据量相对大,存储在服务器,会占用一些服务器资源,但是对于它的优点来说,这个缺点可以忽略了
2 session有什么用 在一次客户端和服务器为之间的会话中,客户端(浏览器)向服务器发送请求,首先cookie会自动携带上次请求存储的数据(JSESSIONID)到服务器,服务器根据请求参数中的JSESSIONID到服务器中的session库中查询是否存在此JSESSIONID的信息,如果存在,那么服务器就知道此用户是谁,如果不存在,就会创建一个JSESSIONID,并在本次请求结束后将JSESSIONID返回给客户端,同时将此JSESSIONID在客户端cookie中进行保存 客户端和服务器之间是通过http协议进行通信,但是http协议是无状态的,不同次请求会话是没有任何关联的, ...

Oracle迁移到PGSQL经验总结
1 数据源配置1.1 驱动包配置 在pom文件中添加pgsql数据驱动依赖:
12345<dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.2.14.jre7</version> </dependency>
1.2 修改数据源 在配置文件中修改数据源连接:
1234jdbc.driverClassName=org.postgresql.Driverjdbc.url=jdbc:postgresql://xxx.xxx.xxx.xxx:xxxxx/xxxxjdbc.username=********jdbc.password=********
2 数据迁移2.1 导出表结构及数据2.1.1 使用navicat视图工具(不推荐) 使用navicat视图工具导出Oracle表结构及所有数据,PLSQL 工 ...
spring中bean配置和bean注入
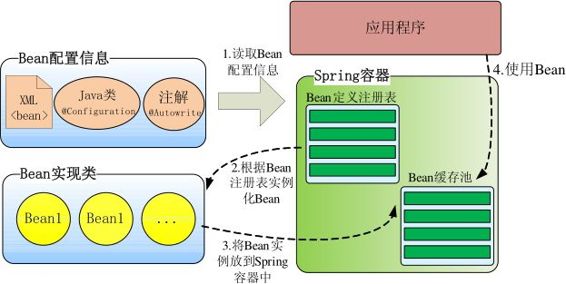
bean与spring容器的关系
Bean配置信息定义了Bean的实现及依赖关系,Spring容器根据各种形式的Bean配置信息在容器内部建立Bean定义注册表,然后根据注册表加载、实例化Bean,并建立Bean和Bean的依赖关系,最后将这些准备就绪的Bean放到Bean缓存池中,以供外层的应用程序进行调用。
1 bean配置bean配置有三种方法:
基于xml配置Bean
使用注解定义Bean
基于java类提供Bean定义信息
1.1 基于xml配置Bean在Spring低版本中,XML中采用的是基于DTD的配置方式,Spring4.0配置升级后是基于Schema的配置方式,虽然升级是向后兼容的,但后者是我们首选的XML配置方式。
一个基本的基于Schema的XML配置模板如下:
12345678910<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" ...

Centos7对外开放端口
Centos7对外开放端口命令集合:1234567891011121314151617(1)查看对外开放的端口状态查询已开放的端口 netstat -anp查询指定端口是否已开 firewall-cmd --query-port=666/tcp提示 yes,表示开启;no表示未开启。(2)查看防火墙状态查看防火墙状态 systemctl status firewalld开启防火墙 systemctl start firewalld 关闭防火墙 systemctl stop firewalld开启防火墙 service firewalld start 若遇到无法开启先用:systemctl unmask firewalld.service 然后:systemctl start firewalld.service(3)对外开发端口查看想开的端口是否已开:firewall-cmd --query-port=6379/tcp
添加指定需要开放的端口(方法一):123456添加指定需要开放的端口:firewall-cmd --add-port=123/tcp --permanent重载入添 ...

VUE无需上传,在浏览器中查看xlsx或xls表格
xlsx-to-table
无需上传,在浏览器中查看xlsx或xls表格,由js-xlsx驱动.在vue-xlsx-table基础上开发,(为了获得完整表头)修改为即使某一列没有数据也获取表头,给列表默认空字符
依赖
vue: ^2.0.0
用法install1npm install xlsx-to-table --save
main.js12import xlsxToTable from 'xlsx-to-table'Vue.use(xlsxToTable, {rABS: false}) //浏览器的FileReader API 有两个方法可以读取本地文件 readAsBinaryString 和 readAsArrayBuffer, 默认rABS为false,也就是使用readAsArrayBuffer
file.vue1234567891011121314151617<template> <div id="app"> <h1>xlsx-to-table</h1&g ...
线程的几种状态转换
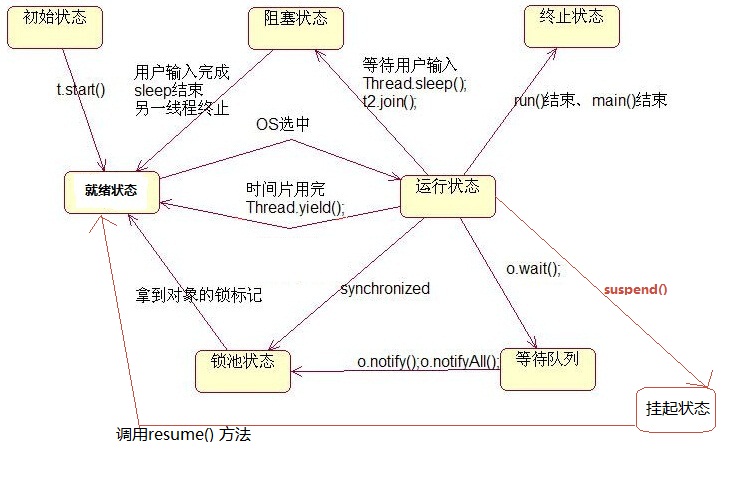
线程的几种状态转换线程在一定条件下,状态会发生变化。线程一共有以下几种状态:
1、新建状态(New):新创建了一个线程对象。
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于“可运行线程池”中,变得可运行,只等待获取CPU的使用权。即在就绪状态的进程除 CPU之外,其它的运行所需资源都已全部获得。
3、运行状态(Running):**就绪状态的线程获取了CPU,执行程序代码。
4、阻塞状态(Blocked):**阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。
阻塞的情况分三种:
(1)、等待阻塞:运行的线程执行wait()方法,该线程会释放占用的所有资源,JVM会把该线程放入“等待池”中。进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify()或notifyAll()方法才能被唤醒,
(2)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入“锁池”中。
(3)、其他阻塞:运行的线程执行sleep()或join()方法 ...
死锁与CPU使用率
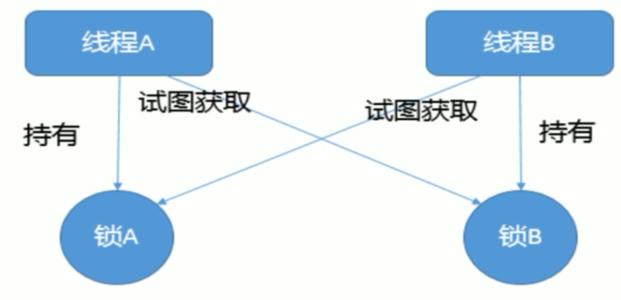
死锁一定会造成cpu使用率飙升吗?这取决于锁的实现,通常锁有两种实现:
ps: 在一个角落看到这篇文章,记录一下;
1 拿不到锁的时候,忙等待,反复探测锁状态,直到拿到锁,进入临界区。这种情况会消耗CPU。
1while (locked);
这种锁,称为自旋锁。比如pthread_spin_lock。
2 拿不到锁的时候,放弃CPU,休眠,离开运行队列,这种情况不会消耗CPU。
1while (locked) sleep(1);
这种锁,称为休眠锁。pthread_mutex就是这种锁。也是最常用的锁。
当然通常不会直接使用sleep实现,因为sleep会导致释放锁后,等锁的线程不能及时醒来干活儿。一般会借助系统调用,比如linux上会使用futex,这个调用可以让等锁线程休眠直到被释放锁的线程唤醒它。等锁线程会执行FUTEX_WAIT休眠, 而unlock的线程会执行FUTEX_WAKE唤醒休眠的等锁线程。
1if (locked) futex(FUTEX_WAIT...);
so,由于自旋锁不会放弃CPU,没有调度开销(进出运行队列),性能要好于休眠锁,只是等锁的时候CPU是 ...
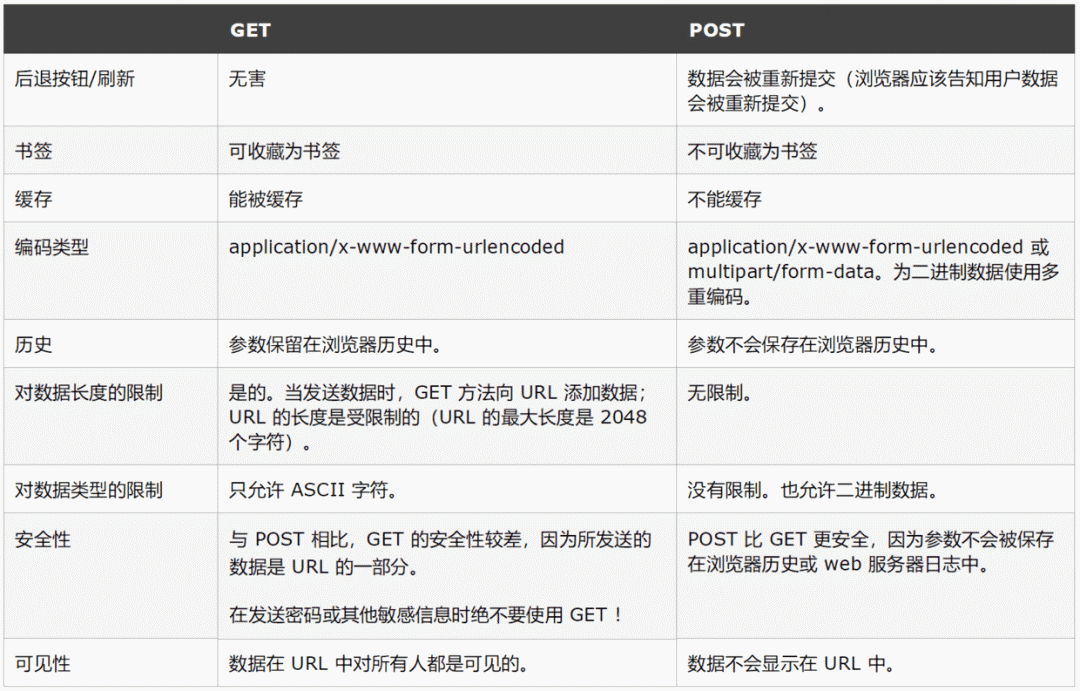
GET和POST的区别
关于GET和POST的区别标准答案在开始之前,先看一下标准答案【来自w3school】长什么样子来保个底。标准答案很美好,但是在面试的时候把下面的表格甩面试官一脸,问题应该也不大。
注意,并不是说标准答案有误,上述区别在大部分浏览器上是存在的,因为这些浏览器实现了 HTTP 标准。
所以从标准上来看,GET 和 POST 的区别基本上可以总结如下:
GET 用于获取信息,无副作用,幂等,且可缓存
POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存
但是,既然本文从报文角度来说,那就先不讨论 RFC 上的区别,单纯从数据角度谈谈。
GET和POST报文上的区别GET 和 POST 只是 HTTP 协议中两种请求方式,而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。
报文格式上,不带参数时,最大区别仅仅是第一行方法名不同,一个是GET,一个是POST
带参数时报文的区别呢?在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中
举个例子,如果参数是 ...

Idea自定义get模板Template(velocity语言开发)
Idea自定义get模板Template(velocity语言开发)因为使用Hibernate想生成get模板带注解@Column(name = “pm_Ht_Model”)
1234567891011private Long pmHtModel;public Long getPmHtModel() { //idea默认get模板 return pmHtModel;}//因为使用Hibernate想生成如下@Column(name = "pm_Ht_Model")public Long getPmHtModel() { //自定义默get模板 return pmHtModel;}
模板使用模板使用的velocity语言.
12345678910111213141516171819@Column(name = "$field.name.replaceAll("[A-Z]", "_$0")")#if($field.modifierStatic ...
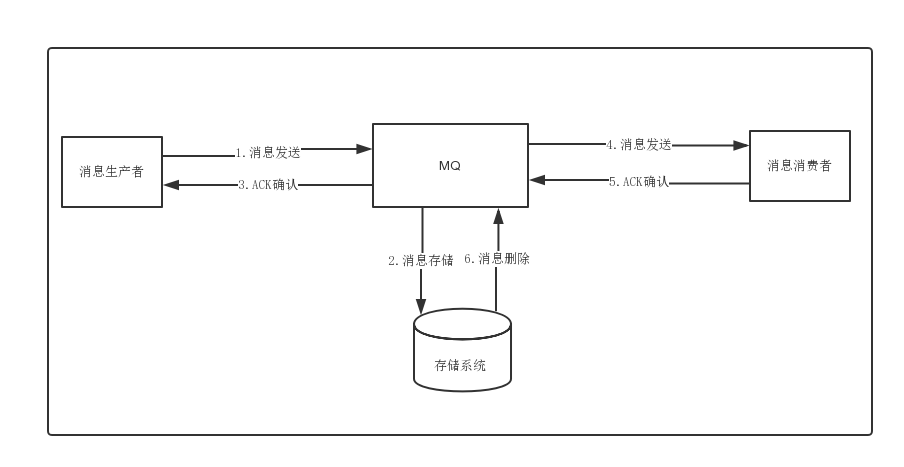
RocketMQ-03
1. 高级功能1.1 消息存储分布式队列因为有高可靠性的要求,所以数据要进行持久化存储。
消息生成者发送消息
MQ收到消息,将消息进行持久化,在存储中新增一条记录
返回ACK给生产者
MQ push 消息给对应的消费者,然后等待消费者返回ACK
如果消息消费者在指定时间内成功返回ack,那么MQ认为消息消费成功,在存储中删除消息,即执行第6步;如果MQ在指定时间内没有收到ACK,则认为消息消费失败,会尝试重新push消息,重复执行4、5、6步骤
MQ删除消息
1.1.1 存储介质
关系型数据库DB
Apache下开源的另外一款MQ—ActiveMQ(默认采用的KahaDB做消息存储)可选用JDBC的方式来做消息持久化,通过简单的xml配置信息即可实现JDBC消息存储。由于,普通关系型数据库(如Mysql)在单表数据量达到千万级别的情况下,其IO读写性能往往会出现瓶颈。在可靠性方面,该种方案非常依赖DB,如果一旦DB出现故障,则MQ的消息就无法落盘存储会导致线上故障
文件系统
目前业界较为常用的几款产品(RocketMQ/Kafka/RabbitMQ)均采用的是消息刷盘至所部 ...
![leetcode-20天[算法]刷题计划](/2021/07/23/leetcode-20%E5%A4%A9-%E7%AE%97%E6%B3%95-%E5%88%B7%E9%A2%98%E8%AE%A1%E5%88%92/leetcode.webp)



